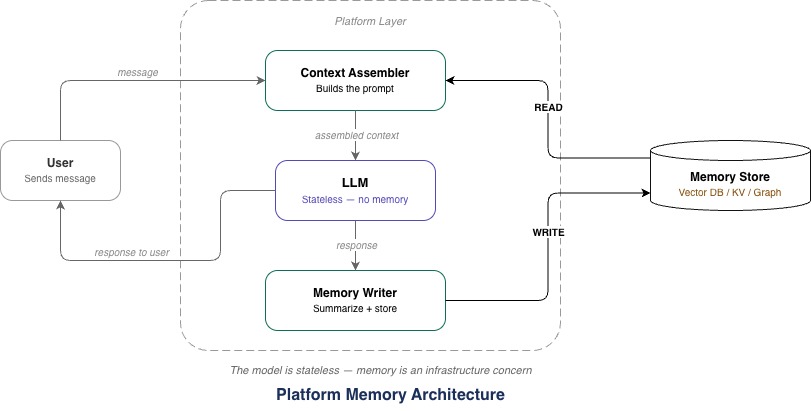
If you have been working with LLMs or building agentic systems, you have probably noticed something that feels counterintuitive at first: the model doesn’t actually remember anything. Every call to the API starts from scratch. The continuity we experience when using tools like Claude or ChatGPT is not a property of the model itself – it is an architectural capability built by the system around the model.
For those of us who have spent years designing distributed systems and thinking about state management, this is a familiar kind of problem. The model is stateless, and memory is an infrastructure concern. And like most infrastructure concerns around memory management, the important consideration is deciding what to retrieve and when.
In this post, I’ll walk through the core architectural concepts behind agentic memory and discuss how it works, how the memory is organized, and where the real engineering tradeoffs show up. For someone evaluating agentic systems for enterprise systems, this should give you a solid foundation for understanding what is actually happening under the hood.
The Statelessness Constraint
Every LLM API call follows the same pattern. You send a prompt, the model generates a response, and the interaction ends. The next call, even if it happens immediately after, starts from a completely blank slate. The model has no awareness of any prior exchange.
Transformer-based models process whatever text is placed in front of them at inference time. There is no session and persistent state inside the model. If we want the agent to behave as though it remembers a conversation from yesterday, we have to explicitly place that context back into the prompt before the model sees it.
This is an important distinction. What looks like “memory” in a product is really context management by the platform layer. The intelligence lives in the model, and the memory lives in the architecture around it.
The Context Window and Its Limits
The context window is the bounded input the model reads on each call. It includes the system prompt, the user’s message, and whatever else the developer has assembled for that turn. The model has full visibility into the contents of this window. Anything outside it does not exist from the model’s perspective.
The simplest approach to memory is to write the entire conversation history into the context window on every call. This works fine for short exchanges. As the conversation grows in agentic AI systems, three problems emerge quickly.
- Every token in the context window is billed on every call. A conversation that grows linearly produces a linearly growing cost per message. By the time the process loops a few times, there will be thousands of tokens required just to maintain continuity.
- Larger context windows take longer to process. A prompt that fits in a few hundred tokens might return in under a second, while a full window can take significantly longer. For real-time or interactive use cases, the latency matters.
- Attention degradation is something that is not widely discussed. Research has shown that models recall information placed at the beginning or end of a long prompt more reliably than information placed in the middle. This is sometimes called the “lost-in-the-middle” effect. A fact can be sitting right inside the context window and still get missed by the model because of where it was placed.
Bigger context windows help, but they do not solve the problem. What we need is an architecture that decides what belongs in the window at any given moment, and that is where memory management patterns play an important role.
Organizing Memory in Tiers
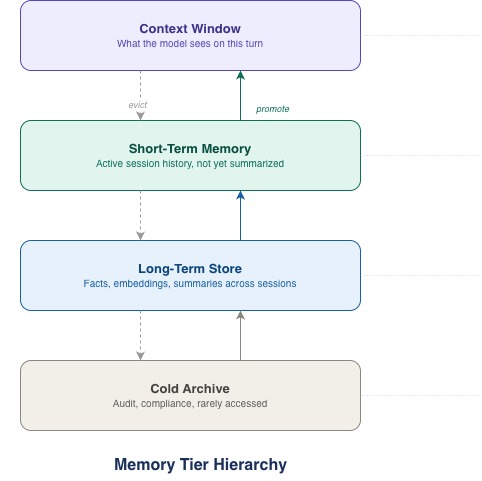
Production agentic systems organize memory into a hierarchy of tiers. This will feel similar to how we design caching strategies for enterprise applications. It draws heavily on the way operating systems manage memory – paging data between fast, expensive storage and slower, cheaper storage based on access patterns.
At the top of the memory stack is the context window, which is fast, expensive, and tightly bounded. Everything the model can see on a given turn lives here. Below it is short-term memory, recent conversation history or task state that has not yet been summarized or evicted. Next is the long-term store, persistent facts, user preferences, summaries of past interactions, and embeddings that survive across sessions. At the bottom of the memory stack is cold storage which is rarely accessed material kept for audit, compliance, or future reference.
Information moves up and down this hierarchy as the agent works. The moment the information becomes relevant to the current conversation, the system retrieves it from long-term storage and promotes it into the context window. When a session ends, the most useful parts of the working context get summarized and written down into the lower tiers.
This is not fundamentally different from how we think about caching in distributed systems. The context window is L1 cache, which is fast, small, and close to the processor. The long-term store is the database. The engineering challenge is to select what you promote, what you evict, and how you keep the working set relevant without blowing your budget.
Types of Memory
Beyond the physical hierarchy outlined above, the field has converged on four functional categories of memory.
- Working memory is whatever currently occupies the context window for the active task. If the agent is helping debug a function, the code and recent messages are in working memory. When the task ends, working memory clears.
- Episodic memory captures records of specific past interactions, anchored in time. It records what happened and when.
- Semantic memory stores facts and knowledge that are independent of any particular interaction. Things like preferred programming language for a coding task, preferred output in JSON object, etc. They apply across sessions wherever they are relevant.
- Procedural memory captures learned patterns and preferences for how things should be done.
These four categories are orthogonal to the tier hierarchy. A semantic memory might live physically in the long-term store and get promoted into the context window the moment it becomes relevant. Most production agents implement at least three of these types, with the emphasis depending on the use case. The right blend is a design decision.
The Hard Part – Retrieval from Memory
When designing agentic systems, retrieval from memory is the harder problem compared to storage.
Writing a fact to a database or indexing a summary in a vector store is straightforward. Mature tooling exists for all of it. The difficult part is deciding what deserves to enter the model’s awareness.
Retrieval is hard because relevance shifts from one message to the next if multiple different tasks and use cases are supported. A good retrieval system surfaces the right items at exactly the right moment and leaves the rest sitting quietly in storage.
Memory management in agentic systems involves tradeoffs that need to be evaluated against the specific use case.
- Recency vs. relevance – Is there a need to retrieve the most recent items or the most semantically similar ones? Most systems blend both, and getting that blend right is an ongoing tuning problem.
- Summarization vs. fidelity – Compressing old context into summaries saves tokens, which reduces cost and latency. But summarization is lossy, and the agent stays confident even after the precise details have quietly disappeared.
- Staleness – A fact that was true six months ago can be wrong today. This remains an open problem, especially for long-running agents.
- Memory poisoning – Long-term memory is also a long-term attack surface. A wrong or malicious entry written months ago will sit there influencing every retrieval until someone notices.
Key Takeaway
Memory systems make sense when the agentic solution needs continuity across sessions, when context compounds over time, or when the agent runs long-horizon tasks where earlier decisions affect later ones. For single-loop or stateless tasks, memory adds complexity without proportional benefit.
If you are evaluating an agentic platform for your organization, it is important to understand what the memory architecture is, how retrieval works, what gets summarized and what gets preserved, and how staleness is handled.
There is no memory within the model itself. The useful question is what the architecture around the model is actually doing for memory management, and what tradeoffs it has accepted to get there.
