In my previous posts, we looked at how to integrate Kafka and Storm for streaming loan data and cleansing the data before ingesting it into processing pipeline for aggregating the data. We also looked at how to leverage Liquibase for managing the relational database in form of immutable scripts that could be version controlled. This fits well with DevOps culture as there is less reliance on manually maintaining the database scripts by automating the process and making it less error prone.
In this post, we’ll enhance the Loan data analysis pipeline to add another application that will ingest the cleansed loan data from Kafka broker and save the data in relational database running in a Docker container. The loan data in relational database could then be used for further analysis by joining the data with other data sources.

As discussed in the previous posts, run the Kafka broker and Storm Topology by running the following commands.
./zookeeper-server-start.bat ../../config/zookeeper.properties
./kafka-server-start.bat ../../config/server.properties
./kafka-topics.bat –create –zookeeper localhost:2181 –replication-factor 1 –partitions 2 –topic raw_loan_data_ingest_mariadb
We read the loan data from a csv file and publish it to Kafka topic. Storm topology cleanses the data to remove the invalid records and also scrubs the data with invalid entries. The cleansed data is then ingested by the Spring boot application that connects to the MariaDB and stores the data in loan_details table.
Kafka Consumer – Spring Boot Application
Run the Spring Boot application by passing following command line arguments to start Kafka Consumer for ingesting cleansed loan records from Topic “raw_loan_data_ingest_mariadb”.
localhost:9092 raw_loan_data_ingest_mariadb
This application uses Spring Data for storing the loan data in MariaDB.
consumerLoanRecords.forEach(conumerRecord -> {
LoanDataRecord loanDataRecord = getLoanRecordEntity(conumerRecord.value().toString());
loanRepository.save(loanDataRecord);
System.out.println("Saved Record --> " + conumerRecord.key() + " | " + conumerRecord.offset() + " | "
+ conumerRecord.partition());
});
This application also runs Liquibase scripts to create a loan_details table for storing the loan records.
Loan Data Cleansing Storm Topology
Run the Storm Topology by passing following command line arguments.
localhost:9092 raw_loan_data_in raw_loan_data_ingest_mariadb
For more details, refer to my previous post on Kafka and Storm integration.
This application srubs the loan records and publish valid loan data on Topic “raw_loan_data_ingest_mariadb”.
Loan Data Record Producer
Run the Kafka Producer by passing following command line arguments to read the loan records from the CSV file and publishes them on Topic “raw_loan_data_in”
localhost:9092 raw_loan_data_in C:\bigdata\LoanStats_2017Q2.csv
Data Pipeline Execution
After starting the Kafka Producer, we can see that loan records are streamed through the data pipeline as depicted in the diagram above and finally the data gets stored in MariaDB.
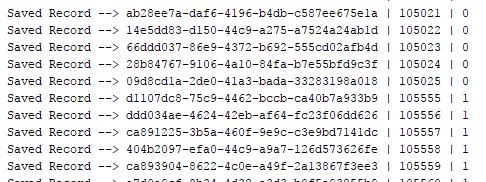
As seen below, some of the consumer record meta-data (Key, Offset and Partition) is printed to the console while the loan records are written to the database.
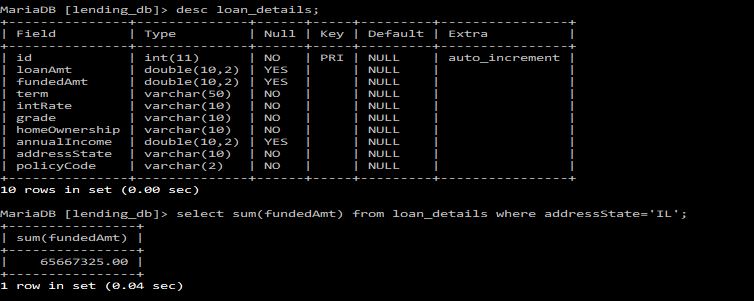
Finally after all the data is processed and written to the database, we run a SQL query to find the total funded amount in IL state that matches exactly with the amount we calculated by running the Spark streaming application.