In my earlier posts on Apache Spark Streaming, we looked at how data can be processed using Spark to compute the aggregations and also store the data in a compressed format like Parquet for future analysis. We also looked at how data can be published and consumed using Apache Kafka which is a distributed message broker for large-scale data processing.
In this post, we’ll build upon the previous posts and take a look at a sample application that integrates both the Apache Kafka and Spark Streaming technologies to provide a very scalable and highly decoupled data pipeline. In a typical scenario, there would be number of event/message producers publishing the data to a Topic on Kafka and multiple consumers of the data each serving a unique use case like real-time analytics, fraud monitoring, customer alerts etc. All the producers and consumers are decoupled from each other and can scale independently without impacting other systems. Kafka also provides message persistence that could help the system recover from errors by playing back the transactions if necessary.
There are 2 applications that we’ll look at in this post. It is assumed that Apache Kafka is already running locally as discussed in Apache Kafka post.
Apache Spark Streaming with Kafka Source
kafka-spark-int-financial-analysis is a Spark Streaming application that consumes the loan data messages from Kafka and processes the data in real-time along with some aggregations. It also writes the data to disk in Parquet format for future analysis.
- Set Spark Configuration
// Set Spark Configuration
SparkConf sparkConf = new SparkConf().setAppName("spark-financial-analysis").setMaster("local[*]");
sparkConf.set("spark.sql.parquet.compression.codec", "snappy");
- Create Java Streaming Context with a batch size of 20 seconds. What this means is that Spark Streaming will collect the loan records received in last 10 seconds and convert them into an RDD
JavaStreamingContext sparkStreamingContext = new JavaStreamingContext(conf, Durations.seconds(20));
- Create Discrete Stream by polling the loan data records on the Kafka Topic
JavaInputDStream<ConsumerRecord<String, String>> loanConsumerRecordStream = KafkaUtils.createDirectStream(
sparkStreamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(Arrays.asList(loanDataIngestTopic), getKafkaConfiguration())
);
- Convert the streams of ConsumerRecord RDD to Java Beans RDD
if (!(loanRecord.isEmpty() || loanRecord.contains("member_id") || loanRecord.contains("Total amount funded in policy code"))) {
// Few records have emp_title with comma separated values resulting in records getting rejected. Cleaning the data before creating Dataset
String updatedLine = loanRecord.replace(", ", "|").replaceAll("[a-z],", "");
String loanRecordSplits[] = updatedLine.split(",\"");
loanDataRecord.setLoanAmt(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[2]));
loanDataRecord.setFundedAmt(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[3]));
loanDataRecord.setTerm(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[5]));
loanDataRecord.setIntRate(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[6]));
loanDataRecord.setGrade(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[8]));
loanDataRecord.setHomeOwnership(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[12]));
loanDataRecord.setAnnualIncome(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[13]));
loanDataRecord.setAddressState(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[23]));
loanDataRecord.setPolicyCode(SparkFinancialAnalysisUtil.cleanRecordField(loanRecordSplits[51]));
} else {
System.out.println("Invalid Record line " + loanRecord);
}
return loanDataRecord;
}).filter(record -> record.getFundedAmt() != null);
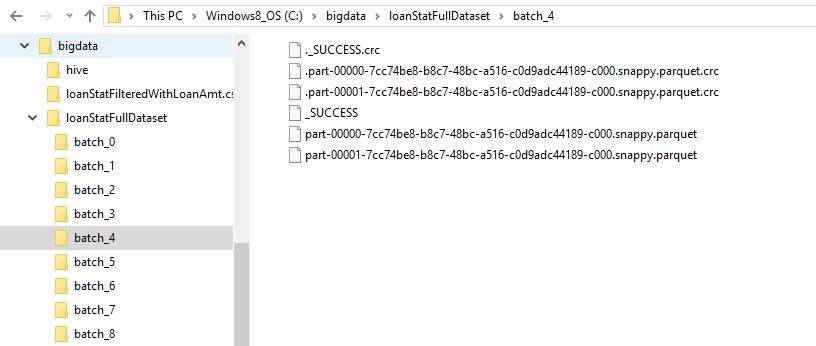
- Create a Dataset of records for the current batch and store the data to the disk in the Parquet format. Note that the data is being stored in a batch specific directly.
loanStatFullDataset.write().mode(SaveMode.Append).parquet("/bigdata/loanStatFullDataset" + "/batch_" + batchNumber.get());
- Read loan data stats from Parquet Files for each micro-batch and combine them to calculate aggregated results. Data from all the batch folders is read and combined together.
Dataset<Row> aggregatedLoanDataParquet = session.read().parquet("/bigdata/loanStatFullDataset/*");
- Run SparkFinancialAnalysisStreamingMain by passing the following command line arguments.
localhost:9092 raw_loan_data_ingest
Spark Streaming application will start polling for loan record messages on Kafka topic “raw_loan_data_ingest”. Since there is no data being published on this Topic yet, we’ll not see any aggregations or data getting stored on the disk.
Loan Data Message Publishing to Kafka
kafka-financial-analysis application has a producer that reads the loan data provided by Lending Club. It reads the data from the loan file line by line and publishes the messages to Kafka. More details are available on my earlier post on Apache Kafka.
- Run LoanDataKafkaProducer by passing the following command line arguments
localhost:9092 raw_loan_data_ingest C:\bigdata\LoanStats_2017Q2.csv
- As we can see in the image below, it took 162 seconds to publish all the records available in the LoanStats_2017Q2 file to Kafka.

After LoanDataKafkaProducer is started, we can see the loan data records getting published to Kafka Topic. Spark Streaming application will now start getting the stream of loan records in a batch interval of 20 seconds. It will process the records received in the batch and save the data to the disk under the respective batch directory.
We can see the current non-empty batch number getting processed and the number of records received in the current batch corresponding to the 20 seconds time interval.


It’s worth noting that there are a total of 9 batches of data and each one of them was written to the disk in the Parquet format as seen in the image below.
It took total 162 seconds to publish all the loan records with Spark Streaming having a batch size window of 20 seconds. Hence it took total 9 batches (162/20) to process all the streaming records.
Finally as seen in the image below, we get the total loan amount funded by lending Club in IL state. This is the aggregated loan amount for IL state and is computed by processing all the loan records that were published and streamed real-time using Kafka. This count matches exactly with the count that we received when the records were processed in batch mode.


3 thoughts on “Financial Data Analysis using Kafka and Spark Streaming”