Architecting business-critical systems require a detailed analysis of non-functional requirements, especially when targeting the public cloud as the hosting platform. The public cloud has additional factors that could impact system SLA. Availability and Reliability of a system are usually considered the most common non-functional requirements among others that could have a major impact on the system architecture. Calculating the availability of a system within a large and complex organization cannot be accomplished easily due to interdependencies between various systems and applications hosted on platforms with multiple infrastructure layers. In this article, we’ll look at various factors that can be taken into consideration when architecting a new system for high availability and reliability in the public cloud.
System Failures
Werner Vogels, CTO at Amazon.com, had famously quoted that “Everything Fails All the Times” and is a true reminder that a highly available system should be architected with the assumption that parts of the system will fail.
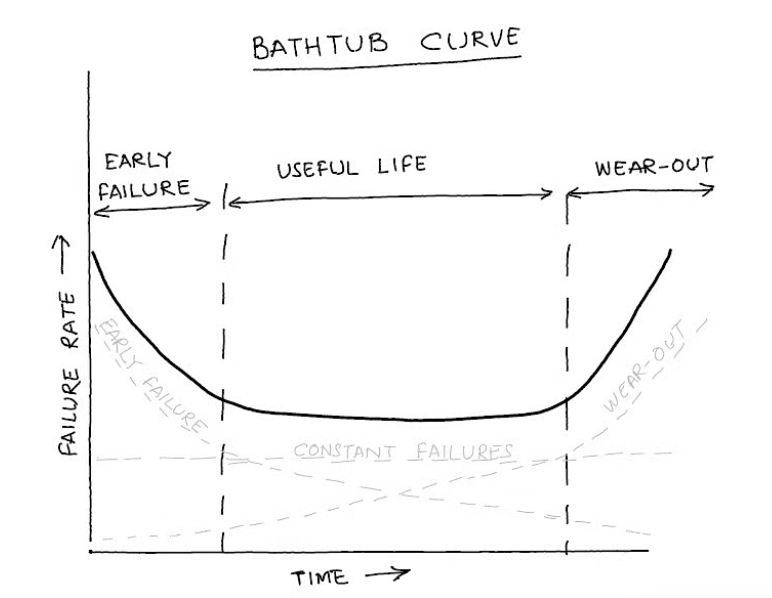
The bathtub curve is widely used in modeling and predicting system failures. It categorizes failures into 3 different types depending on the stage when they show up during system lifecycle.
- Early Failures – These are related to programming or configuration defects and reduces over time as the system becomes stable
- Random Failures (Useful Life) – These are random failures that occur once the product has stabilized
- Wear-out Failures – These are late stage failures that happen due to worn out components
System Availability Overview
System Availability is calculated by modeling the system as an interconnection of all its parts/components. The parts can be either connected in serial or in parallel.
- If failure of a part leads to the system to become unavailable, then the parts are considered to be operating in a series. There is a serial dependency of one part on the other part.
- If failure of one part leads to the other part taking over the responsibility to keep the system operational, then the parts are considered to be operating in parallel. The parts are said to be connected in parallel to form a cluster.
Serial Availability
Consider that a system is made up of 3 components which are connected serially such that failure of any one components results in the system to become unavailable. The combined availability of the system is a product of the availability of individual components.
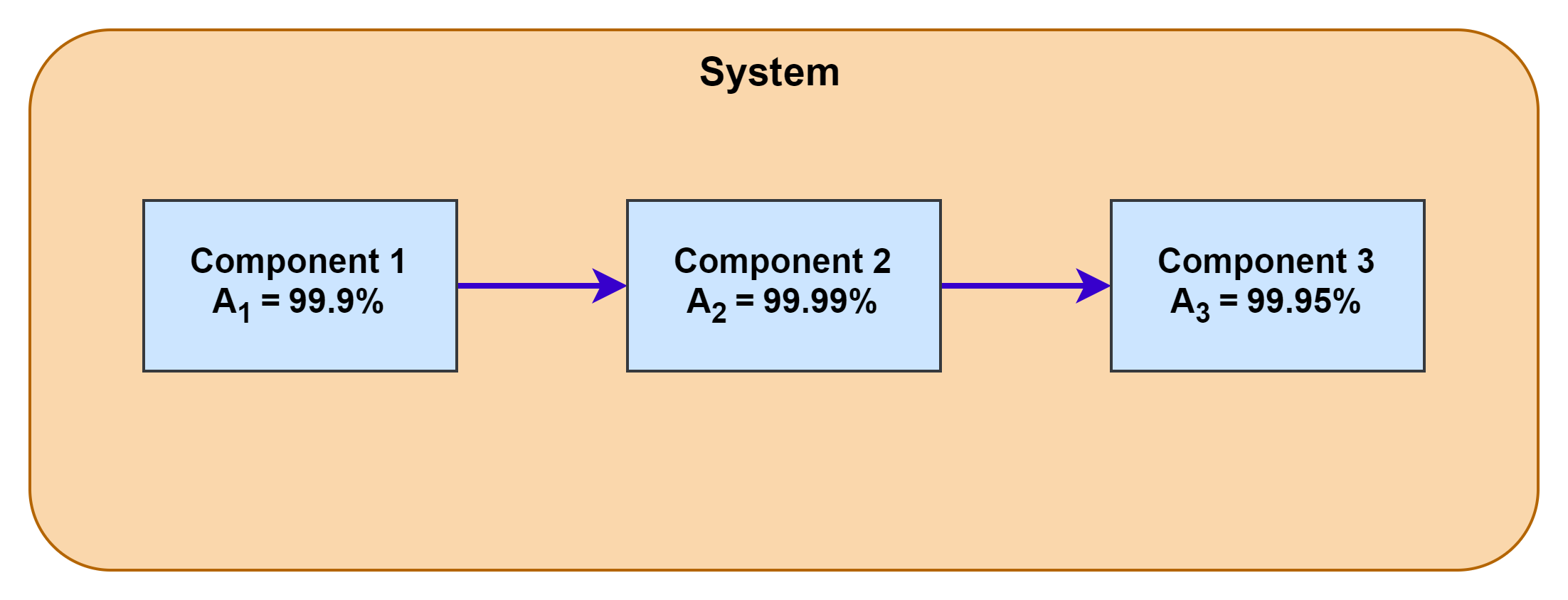
The combined availability of the system can be calculated using below equation:
A = A1 * A2 * A3
Serial Availability (Ax) = 99.9 * 99.99 * 99.95 = 99.84%
As we can see that the overall serial availability of the system drops even below the lowest availability of the component in the system.
Parallel Availability
The system can be duplicated such that the combined system stays operational if either is available. The combined parallel availability can be calculated by first finding the combined unavailability of the system i.e. parallel deployments of the system are unavailable. This combined unavailability can be subtracted from 1 to get the parallel availability of the system.
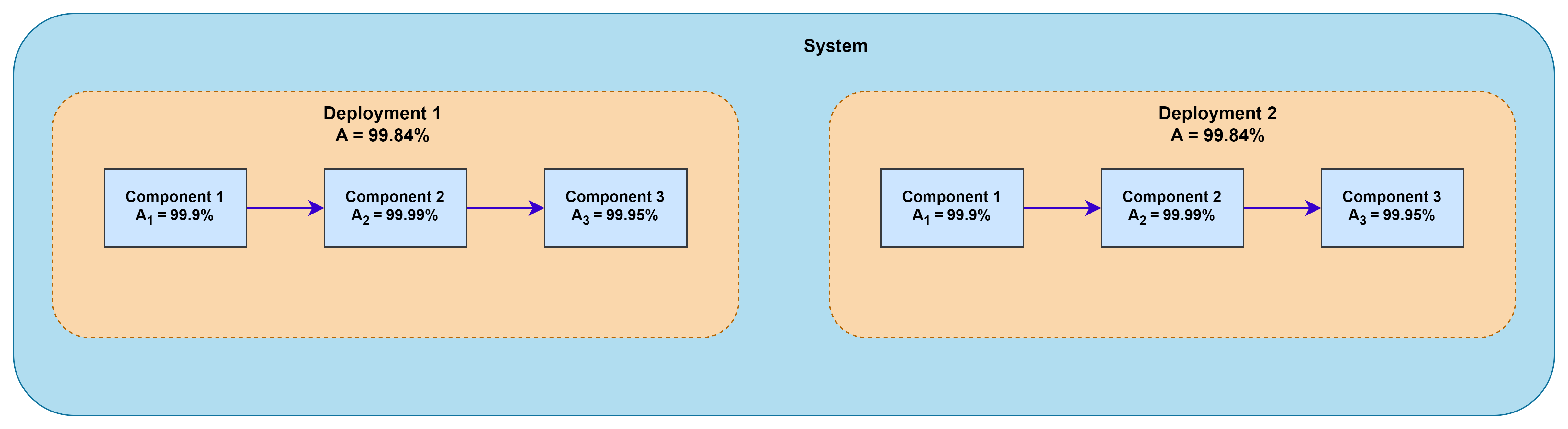
Parallel Availability = 1 – ((1- Ax) * (1- Ax))
Parallel Availability = 1 – ((1 – 0.9984) * (1 – 0.9984)) = 99.999%
This shows that a system with multiple deployments in parallel provides availability which is much higher than the availability provided by single deployment. This however comes with additional cost due to duplication of deployments in multiple distinct sites to get redundancy.
Availability of Individual Components
Availability of individual components can be calculated by estimating the Mean Time Between Failure (MTBF) and MTTR (Mean Time To Recovery). These estimates need to consider both hardware and software failures for the component.
Availability = MTBF / (MTBF + MTTR)
MTBF for a software component is the time interval during which the component remains available before it fails to serve its purpose either due to a failure or due to scheduled miantenance.
System Availability in Cloud
Calculating availability of a system in the cloud is not a simple task due to multiple factors that needs to be taken into consideration. In addition to business service, we need to also consider the availability of underlying infrastructure and network to arrive at a real availability for the system. Below are some of the factors that could influence the overall availability of the system in cloud.
- Compute
- Storage
- Network
- Database
- Dependent Services
- Business Application
Each cloud provider publishes availability SLA for their compute services. These are usually monthly SLA usually in the range of 99.5% for a single compute instance. The parallel availability of compute increases by providing instances in multiple availability zones.
Various network services used within the system like Load Balancers and Direct Connect can have availability ranging between 99.9% to 99.99% depending on the service and the cloud provider. Similarly, we need to consider the availability for database, storage and other dependent services as they could result in a lower overall serial availability.
The most common pattern to get high availability in public cloud is to deploy the system across multiple regions.

System Reliability
System reliability is a qualitative measure based on the probability of a failure-free operation of the system for a specified duration of time. It helps in measuring the frequency and impact of failures.
Mean Time Between Failure (MTBF) = Total operational time for the system / number of failures
A highly reliable system is usually considered to be highly available, however a highly available system may not be always highly reliable. As an example. a system that may be highly available over multiple hours may have a network blip every few minutes that could last few seconds impacting customers. The system might meet the overall availability SLA, however due to regular network connectivity issues it may not be considered reliable if customers see an impact every few minutes.
Reliability of a system deployed in cloud environment can be improved by proactively detecting failures quickly and acting on those failures to minimize customer impact. The system should be designed to be fault tolerant to single instance failures by ensuring that there is enough redundancy to without failures by routing the traffic to redundant instances.

When designing a new system for high availability and reliability in the cloud, important factors to consider are the availability of individual components and the availability of the underlying infrastructure.
A system can be duplicated such that the combined system stays operational if either is available.
Wayne
LikeLike